Query Analyser
Luteijn Automatisering
(KvK: 60276037, BtwNr: NL062594862B01)
Artikelen over automatisering
De Query-Analyser van SQL-Server wordt aldra een van de meest gewaardeerde hulpmiddelen bij het werken met databases. Het is een hulpmiddel vergelijkbaar met TOAD bij Oracle e.a. maar dan veel beter uitgewerkt. Je kunt hem gebruiken om queries op te bouwen en te analyseren, adviezen te krijgen voor indexen, scripts te maken voor databasewijzigingen. Na enige tijd zit je vaker in de analyser, dan in enig andere tool. Je analyseert problemen, maakt overzichten, doet tellingen. Je kunt queries gelanceerd in andere programma's met knippen en plakken binnenhalen en onderzoeken waarom ze foutlopen of niet performen. In Delphi, Visual Basic, de profiler, etc. kan je statements oppakken. Typefouten worden onmiddellijk ontdekt. Je kunt analyser voorstellen laten doen voor indexen. Het executieplan kan inzicht bieden in de wijze waarop SQL-Server queries uitvoert. Je leert dat SQL-Server onder bepaalde omstandigheden een tablescan doet, een tijdelijke tabel of index creëert, een Hashtabel maakt en wat de kosten daarvan zijn.
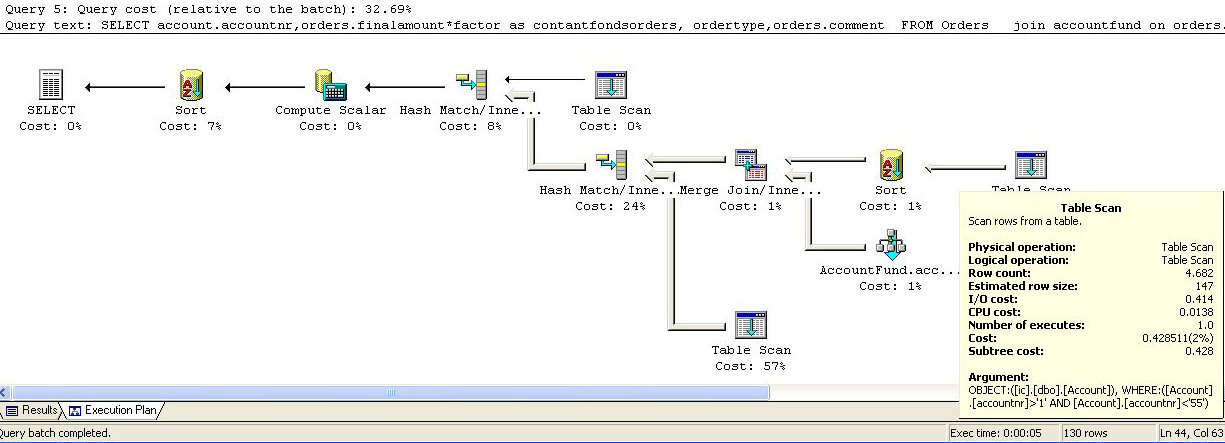
Boven een voorbeeld van een executieplan. Vrijwel alle denkbare elementen van een query zijn voorhanden. Sorteren, hash tabel, table scan, merging, etc. Alleen de index lookup ontbreekt. Wat het allemaal doet: Dat is de eerste tijd volstrekt onduidelijk. Door iets te veranderen in de query kun je het effect bestuderen. Toevoegen van een index geeft soms een enorme verbetering. Zeker als het systeem dat zelf heeft mogen voorstellen. Veel vaker komt het voor dat er geen enkel effect is. Je kunt rechtsklikken op een symbooltje en krijgt meer informatie. SQL-Server is een systeem, dat helemaal gespecialiseerd is op het zo snel mogelijk doorzoeken van grote hoeveelheden data. Daarvoor maakt het gebruik van allerlei indextechnieken. Bij elke query wordt opnieuw een plan gemaakt naar aanleiding van de haar bekende gegevens. Bij kleine queries kan de analysetijd groter zijn, dan de uitvoeringstijd. Het gebruik van indexen is vaak bepaald niet vanzelfsprekend.
Een programmeur op een recordgeoriënteerde database weet niet beter, dan dat de enige manier om snel bij data te komen het gebruik van indexen is. Ook als alle data benaderd moet worden, dan is nog steeds de index de enige zinnige ingang naar de data. Want wat moet je met ongesorteerde data? In SQL-Server wordt daar heel anders over gedacht. De Server is een soort kannibaal. Hij neemt alle resources, die hij kan vinden. Als het mogelijk is de complete tabel in geheugen te halen, dan zal hij het zeker niet laten. Het doen van een tabel scan is onder deze omstandigheden een betrekkelijk goedkope operatie. Een index is in een SQL-database meestal niet meer dan een smallere tabel met verwijzing naar de echt data. Bij een index-lookup moet hij eerst zoeken in de kleine tabel en daarna nog de echte data halen. Dat is kostbaar. Reeds als het systeem verwacht meer dan 10% van de data te moeten lezen, is een table scan goedkoper dan een index lookup.
Om dit in te kunnen schatten worden statistieken bijgehouden. Je kunt desgewenst enige invloed uitoefenen op de nauwkeurigheid van deze statistieken. Bij een samengestelde index op meerdere velden is meestal de statistiek van de eerste kolom beslissend. Het is dus niet handig om een boolean of een kleine enumerated als eerste veld te hebben. Want dan is de kans, dat de statistiek aangeeft minder dan 10% van de data te moeten lezen, tamelijk klein en wordt de index vrijwel nooit gebruikt. Een unieke primaire steutel in het eerste veld van de index geeft betere resultaten. Ook kun je SQL-Server dwingen meerdere indexvelden in de statistiek op te nemen. Dat wordt overigens zelden gedaan. Alleen als de performance van het systeem echt problemen geeft, wordt tijd vrijgemaakt voor index analyses.
Er zijn drie soorten indexen mogelijk bij SQL-Server. Het meest algemeen is de klassieke index op een (primaire) key, die verwijst naar data. Daarnaast bestaat de zogenaamde clustered index. Dat wil zeggen dat de data van de tabel in de volgorde van een zoeksleutel wordt gehouden. Dat is handig als je vrijwel altijd volgens dezelfde samengestelde key de database doorloopt. Je kunt dan op die sleutel sneller bij de data komen. Pas bij een query, die meer dan 20% van de data raakt, wordt toch een table scan gedaan. Ook de andere indexen refereren in dat geval naar de clustered index i.p.v. naar het recordnummer. Het in een bepaalde volgorde houden van de data heeft natuurlijk een prijs bij het inserten van nieuwe records. De derde soort index is er een, waarmee alle gevraagde data gevonden kan worden zonder naar de data te hoeven. Wanneer je denkt aan een index als een smallere instantie van de hele tabel, dan klinkt dat niet onlogisch. Het kan dan handig zijn om getalskolommen toe te voegen aan de index om te voorkomen, dat ook de rest van de data gehaald moet worden. In dat geval gebruikt het systeem altijd de index.
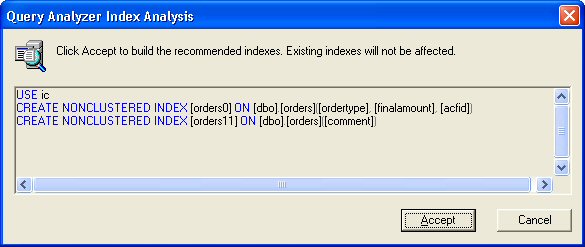
Via de menukeuze Perform index analysis kun je aan het systeem vragen de query in het analysevenster te onderzoeken op performance verbeteringen. Boven zien jullie het resultaat van zo'n analyse. De bovenste voorgestelde index is een typisch een voorbeeld van het derde type. Het tweede veld is de getalskolom, waarin we primair geïnteresseerd zijn. Als je op Accept drukt, dan worden de voorgestelde indexen direct aangemaakt. Je maakt mee, dat het opbouwen van de index minder tijd kost, dan voorheen de complete query. Kennelijk is SQL-Server goed in het snel opbouwen van indexen. Maar als je meerdere instanties hebt van de database, dan is het belangrijk deze gemakkelijk door te kunnen voeren op elke database. In de enterprise manager kun je een voorgestelde indexen eveneens aanmaken en automatisch het bijbehorend script laten genereren.

Kenners zullen zien, dat het bovenstaande script afwijkt van hetgeen gegenereerd wordt door de enterprise manager. Het probleem met gewone scripts is, dat het moeilijk is om af te breken, als er iets fout gaat. Per ongeluk voor de tweede maal hetzelfde script draaien, kan vernietiging van data ten gevolge hebben. In het ergste geval breekt de conversie af halverwege en ben je de data van een belangrijke tabel volledig kwijt. Door het SQL-statement om te zetten naar een string en hem vervolgens aan te bieden aan het EXEC-commando ben je in staat om het resultaat van een statement te testen en passende maatregelen, zoals b.v. een rollback te nemen. Een ander element in het bovenstaande statement is het gebruikt van de 'IF NOT EXIST' constructie. Het systeem geeft als een index al bestaat een fout en breekt af, terwijl je in de praktijk de uitvoering van het statement gewoon wilt overslaan en verder wilt gaan met het volgende.
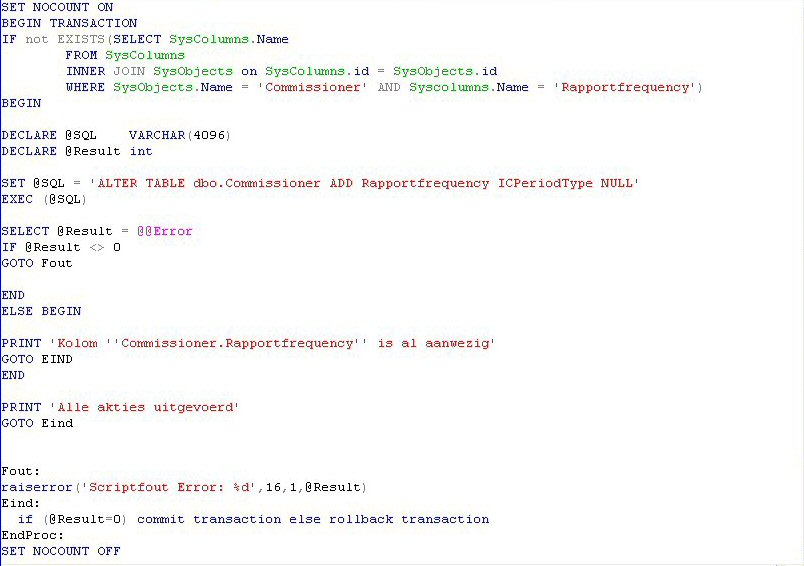
Een ander voorbeeld van een conditioneel script zien jullie hier vlak boven. Het is de bedoeling alleen de nieuwe kolom 'Rapportfrequency' toe te voegen als hij er nog niet is. In het andere geval zijn we tevreden met de melding, dat het script al ene keertje gedraaid heeft en dat er niets gedaan hoeft te worden. Alleen als er werkelijk iets fout gaat, moet er een rollback plaatsvinden. Het is eventjes wat meer werk, maar het scheelt vele rampen als je echte controle verwerft over het uitvoeren van databasewijzigingen. Het GOTO-statement werkt alleen binnen een batch. De scripts gegenereerd door de enterprise manager zijn meestal een samenstelling van meerdere batches. Bij mislukken van de ene batch kan het voorkomen, dat de andere batches gewoon uitgevoerd worden, terwijl je eigenlijk eerst het probleem zou willen oplossen.

De analyse van een kleine query kan gemakkelijk meer tijd kosten, dan de uitvoering. Een oplossing is de query vooraf in de database op te slaan en te laten analyseren, zodat er tijdens de reguliere uitvoering geen analyse van het statement meer nodig is. Speciaal geldt dit voor operaties, waarbij slechts een record gemoeid is. Boven wordt een record afgevoerd door het onzichtbaar te maken in de gebruikte view. I.p.v. het DELETE-commando wordt en update gedaan op het veld DelDate. Deze techniek doet denken aan de ouderwetse Delete-vlag in een DBase database. De data wordt niet fysiek verwijderd, maar alleen onzichtbaar gemaakt. Desgewenst kan het record naderhand teruggehaald worden of hergebruikt. Ik weet niet of nu echt enthousiast ben over deze methode...
Recentelijk had ik een probleem met een database. Per ongeluk waren tijdens een reparatie onbedoeld allerlei andere records weggegooid. De gebruiker had dit niet direct door en werkte verder. Of de weggegooide records eventjes opnieuw gemaakt konden worden? Daartoe ben ik een halve dag bezig geweest met de query-analyser om de gaten te detecteren. Het verschil veld had dus nul moeten zijn. Door records aan te maken ter hoogte van het verschil in de juiste tabellen kon de consistentie weer hersteld worden. Zoals ook in andere databases is het gebruik van View's belangrijk bij het raadplegen van data. Het biedt de mogelijkheid gebruikers de toegang door vertrouwelijke data te ontzeggen. Reportgenerators werken het best met een beperkt aantal tabellen. Een view als een soort kunstmatige tabel kan grote voordelen hebben.
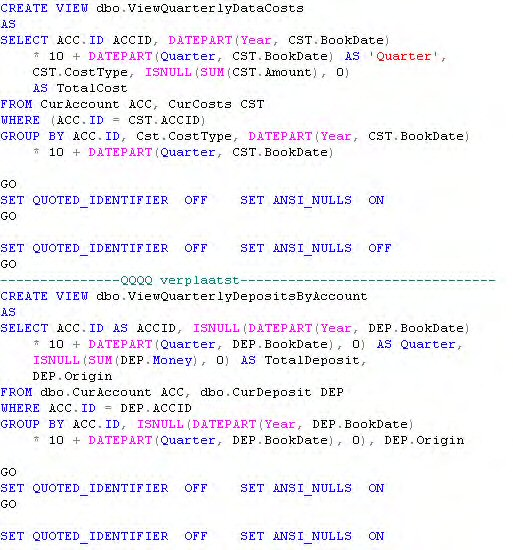
SQL-Server kan op het gebied van View's meer dan anderen. Het is namelijk mogelijk om view's te updaten alsof het gewone tabellen is. De grootst mogelijk voorzichtigheid wordt geadviseerd. Elk SQL-statement is toegestaan in een view. Het updaten van een veld ontstaan door sommatie of group by zal niet mogelijk zijn. Ook kunnen er enorme performance problemen ontstaan, omdat je het zicht verliest op de onderliggende data. Je kunt het wel veilig doen bij view's op één tabel. Maar het beste is om View's alleen te lezen. Hieronder een script met view's. Dit is een door de enterprise manager gegenereerd script. Kenmerkend zijn de overbodige statements met ANSI_NULLS en meerdere batches gescheiden door het GO-statement. Persoonlijk denk ik, dat Microsoft best eens wat energie zou mogen steken om database onderhoud wat stabieler en leesbaarder te maken.